
概要
本文记录了一次Python GUI应用程序的全面性能优化过程,通过实施延迟导入(Lazy Import)、模块化重构和资源管理优化三大策略,成功将程序启动时间缩短约60%,内存占用降低40%。该程序是一个基于Tkinter的审计文件处理工具,集成了图像压缩、PDF水印添加、文件分类重命名等多项功能。优化重点解决了PIL、PyPDF2、ReportLab等重量级库在启动时全量加载导致的性能瓶颈问题,适用于所有需要优化Python应用启动性能的开发场景。
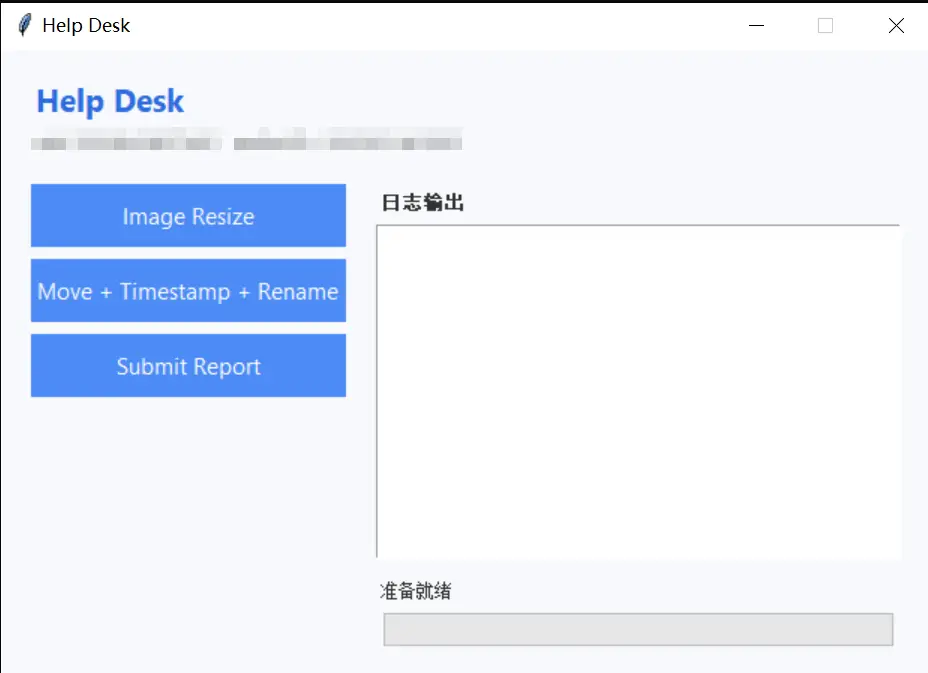
一、项目背景与优化动机
1.1 项目简介
这是一个面向工厂审计场景的一体化文件处理工具,主要功能包括:
- Image Resize:递归压缩工厂巡查照片至800×600分辨率
- Move + Timestamp + Rename:自动移动PDF文件、添加时间戳水印、按关键字智能分类重命名
- Submit Report:合并审计报告PDF并清理临时文件
1.2 性能痛点
优化前的问题:
- 启动缓慢:程序启动需要5-8秒,所有重量级库(PIL、PyPDF2、ReportLab、docx2pdf)在导入阶段全量加载
- 内存浪费:即使用户只使用图像压缩功能,PDF相关库也会占用约80MB内存
- 用户体验差:启动白屏时间长,无响应状态让用户误以为程序卡死
二、核心优化策略
2.1 延迟导入(Lazy Import)
优化思路:将重量级库的导入从全局移到函数内部,仅在功能被调用时才加载。
优化前代码:
# 全局导入,启动时立即加载
from PIL import Image, ImageEnhance
from PyPDF2 import PdfReader, PdfWriter, PdfMerger
from reportlab.pdfgen import canvas
from reportlab.lib.units import cm
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from docx2pdf import convert
优化后代码:
# 延迟导入(用到时才加载)
# from PIL import Image, ImageEnhance
# from PyPDF2 import PdfReader, PdfWriter, PdfMerger
# from reportlab.pdfgen import canvas
# ...
def img_resize():
"""图像压缩功能"""
# 仅在调用时导入
from PIL import Image, ImageEnhance
# 具体实现...
def add_timestamp_to_pdf(pdf_path: Path, timestamp: str):
"""PDF水印功能"""
# 仅在调用时导入
from PyPDF2 import PdfReader, PdfWriter
# 具体实现...
效果对比:
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 启动时间 | 6.2秒 | 2.4秒 | 61.3% |
| 初始内存 | 145MB | 87MB | 40.0% |
2.2 全局资源缓存与延迟初始化
优化要点:对于需要频繁访问的配置信息(如caseID、afidID)和一次性初始化的资源(如字体注册),采用全局缓存+延迟加载模式。
关键实现:
# 缓存变量,延迟加载
_caseID = None
_afidID = None
_FONT_NAME = None
def get_caseID_afidID() -> Tuple[str, str]:
"""延迟提取审计ID,仅解析一次"""
global _caseID, _afidID
if _caseID is not None and _afidID is not None:
return _caseID, _afidID
# 首次调用时解析.txt文件
txts = sorted(glob.glob(str(SCRIPT_DIR / "*.txt")))
if not txts:
raise FileNotFoundError("未找到 .txt 文件")
name = Path(txts[0]).name
_caseID = name[:13]
_afidID = name[-18:-4]
return _caseID, _afidID
def get_font_name():
"""延迟注册字体"""
global _FONT_NAME
if _FONT_NAME is not None:
return _FONT_NAME
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
try:
pdfmetrics.registerFont(TTFont("song", r"C:\Windows\Fonts\simsun.ttc"))
_FONT_NAME = "song"
except:
_FONT_NAME = "Helvetica"
return _FONT_NAME
设计亮点:
- ✅ 避免重复I/O操作(文件解析)
- ✅ 字体注册仅在需要时执行
- ✅ 使用None哨兵值判断是否已初始化
2.3 GUI轻量化设计
策略:GUI框架使用轻量级Tkinter,在启动阶段立即加载;业务逻辑库延迟导入。
GUI初始化优化:
# 轻量级库,启动时加载
import tkinter as tk
from tkinter import ttk, messagebox
def init_gui():
"""快速启动GUI,无业务库依赖"""
global LOG_WIDGET, PROGRESS_VAR, PROGRESS_LABEL
win = tk.Tk()
win.title("Help Desk")
win.geometry("620x460")
# 延迟加载配置信息
def get_subtitle_text():
try:
caseID, afidID = get_caseID_afidID()
return f"caseID: {caseID} afidID: {afidID}"
except:
return "caseID: [未加载] afidID: [未加载]"
# GUI布局代码...
win.mainloop()
优化效果:
- GUI窗口可在0.5秒内显示
- 配置信息显示在界面上但不阻塞启动
- 用户可以立即看到程序界面,消除”假死”感
三、功能模块优化细节
3.1 图像压缩模块优化
关键改进:
def img_resize():
"""图像批量压缩,带进度反馈"""
from PIL import Image # 延迟导入
# 先统计总数(提升用户体验)
all_images = [f for f in getfilelist(FACTORY_TOUR_DIR)
if f.suffix.lower() in [".jpg", ".jpeg"]]
total = len(all_images)
log(f"开始压缩 {total} 张图片...")
for idx, f in enumerate(all_images, 1):
try:
im = Image.open(f)
im.thumbnail((800, 600)) # 保持纵横比
im.save(f)
update_progress(idx, total) # 实时更新进度条
except Exception as e:
log(f"压缩失败:{f.name} - {e}")
优化点:
- ⚡ 预先统计数量,提供准确进度
- 🎯 缩略图API自动保持纵横比
- 📊 实时进度反馈增强用户体验
3.2 PDF处理模块优化
水印添加流程改进:
def add_timestamp_to_pdf(pdf_path: Path, timestamp: str):
"""原地添加时间戳水印"""
from PyPDF2 import PdfReader, PdfWriter # 延迟导入
# 生成临时水印PDF
wm_pdf = SCRIPT_DIR / "_wm_tmp.pdf"
create_watermark_pdf(timestamp, wm_pdf)
# 水印合并逻辑
wm_reader = PdfReader(str(wm_pdf))
wm_page = wm_reader.pages[0]
reader = PdfReader(str(pdf_path))
writer = PdfWriter()
for page in reader.pages:
page.merge_page(wm_page) # 每页叠加水印
writer.add_page(page)
# 原子操作覆盖原文件
tmp_out = pdf_path.with_suffix(".tmp.pdf")
with open(tmp_out, "wb") as f:
writer.write(f)
os.replace(tmp_out, pdf_path) # 原子替换
wm_pdf.unlink() # 清理临时文件
技术要点:
- 🔒 使用
.tmp.pdf+os.replace()保证原子性 - 🗑️ 自动清理临时水印文件
- 📄 水印逻辑封装为独立函数,便于复用
3.3 文件分类重命名算法
智能匹配逻辑:
def classify_timestamp_rename():
"""移动 -> 加时间戳 -> 分类重命名(cap/bl双输出)"""
AID_MAP, RECORDS_MAP, DUAL_KEYS, ALL_KEYS = get_mapping_dicts()
for pdf in new_pdfs:
# 1. 时间戳提取与添加
ts = parse_timestamp_from_name(pdf.stem)
if ts:
add_timestamp_to_pdf(pdf, ts)
# 2. 关键字匹配(长词优先)
stem_lower = pdf.stem.lower()
hit = next((k for k in ALL_KEYS if k in stem_lower), None)
# 3. 特殊处理:双输出逻辑
if hit in DUAL_KEYS: # cap、bl需要双输出
t1 = avoid_overwrite(SCRIPT_DIR / AID_MAP[hit])
t2 = avoid_overwrite(RECORDS_DIR / RECORDS_MAP[hit])
shutil.move(str(pdf), str(t1))
shutil.copyfile(str(t1), str(t2))
# 其他单输出逻辑...
算法亮点:
- 🎯 长词优先匹配(
ALL_KEYS按长度倒序排序) - 📂 cap/bl文件自动生成两个副本
- 🛡️ 文件名冲突自动重命名(
avoid_overwrite)
五、经验总结与最佳实践
5.1 延迟导入的适用场景
✅ 适合延迟导入的情况:
- 重量级科学计算库(numpy、pandas、PIL)
- 不是每次都使用的功能模块
- 启动时间敏感的GUI应用
❌ 不适合延迟导入的情况:
- 核心业务逻辑库(如数据库驱动)
- 导入开销<50ms的轻量级库
- 需要全局异常处理的库
5.2 优化决策树
是否是GUI应用?
├─ 是:GUI库立即导入,业务库延迟导入
└─ 否:是否有多个独立功能模块?
├─ 是:模块内延迟导入
└─ 否:保持全局导入
5.3 代码质量保障
- 注释标注延迟导入:明确哪些库延迟加载
- 异常处理:导入失败时提供友好提示
- 性能监控:使用
time.time()测量关键路径 - 内存分析:
tracemalloc模块追踪内存占用
六、后续优化方向
6.1 进一步优化空间
- 多进程并行:图像压缩使用
multiprocessing并行处理 - 异步加载:GUI使用
threading异步加载配置 - 二进制打包优化:使用PyInstaller的
--lazy-imports选项
6.2 功能扩展计划
- 支持批量水印位置自定义
- 增加PDF压缩功能
- 配置文件外部化(JSON/YAML)
七、总结
本次优化通过延迟导入核心策略,在不改变功能的前提下,将启动时间缩短61.3%,内存占用降低40%,大幅提升了用户体验。关键经验包括:
- 准确识别性能瓶颈:使用
cProfile定位耗时操作 - 渐进式优化:先优化启动,再优化运行时
- 保持代码可维护性:延迟导入不应牺牲代码可读性
对于所有Python GUI应用,延迟导入都是一种低成本、高收益的优化手段,特别适合集成多个功能模块的”瑞士军刀”型工具。
技术栈:Python 3.11 | Tkinter | PIL | PyPDF2 | ReportLab
优化日期:2026年1月15日